
티스토리 뷰
환율 정보 저장하기

from bs4 import BeautifulSoup
import urllib.request as req
import datetime
# HTML 가져오기
url = "https://finance.naver.com/marketindex/"
res = req.urlopen(url)
# HTML 분석하기
soup = BeautifulSoup(res, "html.parser")
# 원하는 데이터 추출하기
price = soup.select_one("div.head_info > span.value").string
print("usd/krw", price)
# 저장할 파일 이름 구하기
t = datetime.date.today()
fname = t.strftime("%Y-%m-%d") + ".txt"
with open(fname, "w", encoding="utf-8") as f:
f.write(price)
cron 사용하기
-
nano 에디터 설치

-
.bash_profile 변경

-
수정 후 임시 적용
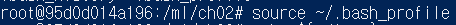
-
변경 확인

-
cron 설치

-
cron 실행

-
매일 아침 7시에 everyday-dollar.py 실행

crontab 설정방법
| [서식] crontab (분) (시) (일) (월) (요일) < 실행할 명령어의 경로 > |
-
각 필드에 입력하는 값
| 항목 | 설명 |
| 분 | 0-59 |
| 시 | 0-23 |
| 일 | 1-31 |
| 월 | 1-12 |
| 요일 | 0-7(0과 7은 일요일) |
-
숫자 외 입력
| 이름 | 사용 예 | 설명 |
| 리스트 | 0, 10, 30 | 0, 10, 30을 각각 지정 |
| 범위 | 1-5 | 1 ~ 5 지정 |
| 간격 | */10 | 10간격으로 지정 |
| 와일드카드 | * | 모두 지정 |
'Machine Learning' 카테고리의 다른 글
| 머신러닝 개요, scikit-learn (0) | 2020.09.20 |
|---|---|
| 크롤링과 스크레이핑 - Scrapy를 이용한 스크레이핑 (0) | 2020.09.19 |
| 크롤링과 스크레이핑 - 웹 API로 데이터 추출 (0) | 2020.09.19 |
| 크롤링과 스크레이핑 - 웹 브라우저를 이용한 스크레이핑(selenium, 헤드리스 파이어폭스) (0) | 2020.09.19 |
| 크롤링과 스크레이핑 - 로그인이 필요한 사이트에서 다운받기 (0) | 2020.09.17 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- gradle
- mapreduce
- 하둡
- JSON
- hadoop
- I/O Mechanisms
- Allocation methods
- jdbc
- Disk Scheduling
- Flume
- vmware
- SPARK
- oracle
- Disk System
- File Protection
- Free space management
- Variable allocation
- I/O Services of OS
- 빅데이터
- SQL
- 빅데이터 플랫폼
- linux
- Spring
- springboot
- aop
- Replacement Strategies
- HDFS
- Java
- maven
- RAID Architecture
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
글 보관함