
티스토리 뷰
다중 출력
<< MultipleOutputs >>
- 다중출력
- 구분값에 따라서 여러 개의 결과 파일을 출력할 때 사용
- GenericOptionParser의 -D옵션에 정의한 구분속성에 따라서 각각의 output파일이 생성될 수 있도록 작업
1. Mapper
- GenericOptionParser테스트할 때와 동일하게 구현 단, 각각의 작업을 구분할 수 있도록
outputkey에 구분 문자열을 추가한다.
2. Reducer
- mapper가 보내오는 출력 데이터에서 구분자 별로 개별 output파일이 생성될 수 있도록 처리
- setup메소드 : 리듀서가 처음 실행될 때 한번 실행되는 메소드
MultipleOutputs를 선언하고 생성할 수 있도록 처리
- reduce메소드 : MultipleOutputs객체의 write를 호출해서 정의해놓은 구분 문자열
(up, down, equal)별로 각각 출력할 수 있도록 구현
- cleanup 메소드 : 리듀서 작업이 종료될 때 호출되는 메소드
MultipleOutputs객체를 종료(반드시 처리)
3. Driver
- MultipleOutputs로 출력될 경로를 정의해 준다.
- 모든 path에 prefix로 구분문자열(up, down, equal)이 연결될 수 있도록 처리 -
상승마감, 하락마감, 동일 다중 값 출력
-
Mapper
< MultiStockMapper.java >
package mapreduce.exam.multioutput.stock;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MultiStockMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text outputKey = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
if(key.get() > 0) {
String[] line = value.toString().split(",");
String year = line[2].substring(0,4);
float resultValue = Float.parseFloat(line[6]) -
Float.parseFloat(line[3]);
if(resultValue > 0) { // 상승마감
outputKey.set("up,"+ year);
context.write(outputKey, one);
} else if (resultValue < 0) { // 하락마감
outputKey.set("down," + year);
context.write(outputKey, one);
} else if (resultValue == 0) { // 동일
outputKey.set("equal," + year);
context.write(outputKey, one);
}
}
}
}
-
Reducer
< MultiStockReducer.java >
package mapreduce.exam.multioutput.stock;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class MultiStockReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable resultVal = new IntWritable(); // 결과 값을 저장할 변수
private Text resultKey = new Text(); // 결과 키를 저장 할 변수
private MultipleOutputs<Text, IntWritable> multiOut;
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// MultipleOutputs객체 생성
multiOut = new MultipleOutputs<Text, IntWritable>(context);
}
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
multiOut.close();
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 1. Mapper에서 전달받은 key에서 구분자(,)를 기준으로 분리 (구분값,key)
String[] keyarr = key.toString().split(",");
resultKey.set(keyarr[1]); // 년도 데이터를 key로 정의
// 2. keyarr[0]에 저장된 각 구분값으르 기준으로 처리
if(keyarr[0].equals("up")) {
int sum = 0;
for(IntWritable value : values) {
sum = sum + value.get();
}
resultVal.set(sum);
// 3. MultipleOutputs를 이용해서 출력 처리를 할 것이므로 Context객체의 write를
// 호출하지 않고 MultipleOutputs의 write를 이용하여 결과를 남긴다.
multiOut.write("up", resultKey, "resultVal");
} else if(keyarr[0].equals("down")) {
int sum = 0;
for(IntWritable value : values) {
sum = sum + value.get();
}
resultVal.set(sum);
multiOut.write("down", resultKey, "resultVal");
} else if(keyarr[0].equals("equal")) {
int sum = 0;
for(IntWritable value : values) {
sum = sum + value.get();
}
resultVal.set(sum);
multiOut.write("equal", resultKey, "resultVal");
}
}
}
-
Driver
< MultiStockDriver.java >
package mapreduce.exam.multioutput.stock;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MultiStockDriver extends Configured implements Tool{
@Override
public int run(String[] optionlist) throws Exception {
// 1. 사용자가 입력한 옵션을 처리하기 위해서 GenericOptionParser객체를 활용
GenericOptionsParser optionParser =
new GenericOptionsParser(getConf(), optionlist);
String[] otherArgs = optionParser.getRemainingArgs();
// 2. job생성
Job job = new Job(getConf(), "multiout_stock");
job.setMapperClass(MultiStockMapper.class);
job.setReducerClass(MultiStockReducer.class);
job.setJarByClass(MultiStockDriver.class);
// 3. input, output 포맷정의
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 4. 리듀서의 출력데이터 key, value의 타입
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5. hdfs에 저장된 파일을 읽고 처리결과를 저장할 수 있도록 path정의
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 6. output파일을 세 개 생성할 것이므로 MultipleOutputs객체를 통해 output이 되도록 설정
MultipleOutputs.addNamedOutput(job, "up",
TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "down",
TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "equal",
TextOutputFormat.class, Text.class, IntWritable.class);
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new MultiStockDriver(), args);
}
}
-
jar 파일 export 후 build path 에 추가


-
실행
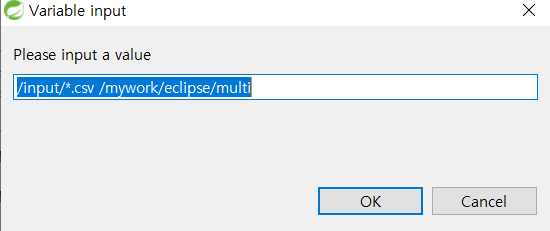
-
결과
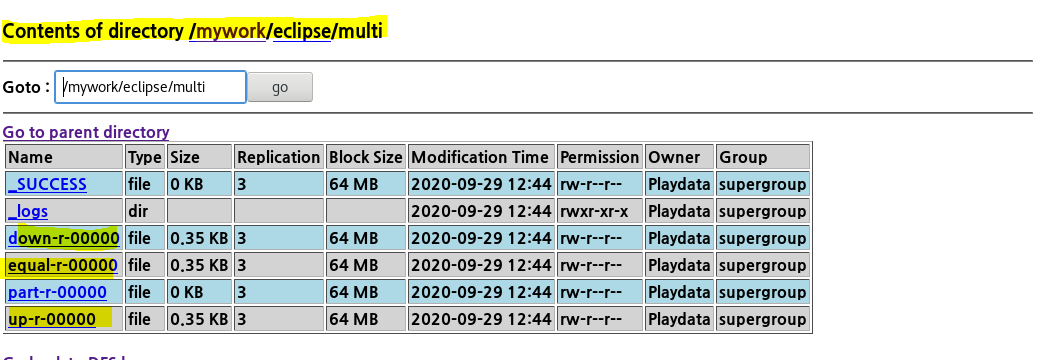

-
항공 데이터 - 출발지연, 도착지연 데이터 다중 출력
-
mapper
package mapred.exam.multioutput.air;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MulitAirMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text outputKey = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
if(key.get()>0) {
String[] line = value.toString().split(",");
if(line!=null & line.length>0) {
if(!line[15].equals("NA") && Integer.parseInt(line[15]) > 0) {
outputKey.set("dep," + line[1]);
context.write(outputKey, one);
}
if(!line[14].equals("NA") && Integer.parseInt(line[14]) > 0) {
outputKey.set("arr," + line[1]);
context.write(outputKey, one);
}
}
}
}
}
-
reducer
package mapred.exam.multioutput.air;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class MulitAirReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable resultVal = new IntWritable();
private Text resultKey = new Text();
private MultipleOutputs<Text, IntWritable> multiOut;
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
multiOut = new MultipleOutputs<Text, IntWritable>(context);
}
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
multiOut.close();
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] keyarr = key.toString().split(",");
resultKey.set(keyarr[1]);
calc(values, resultVal);
if(keyarr[0].equals("dep")) {
multiOut.write("dep", resultKey, resultVal);
} else if (keyarr[0].equals("arr")) {
multiOut.write("arr", resultKey, resultVal);
}
}
public static void calc(Iterable<IntWritable> values,
IntWritable resultValue){
int sum = 0;
for (IntWritable value : values) {
sum = sum + value.get();
resultValue.set(sum);
}
}
}
-
driver
package mapred.exam.multioutput.air;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MulitAirDriver extends Configured implements Tool {
@Override
public int run(String[] optionlist) throws Exception {
GenericOptionsParser optionParser =
new GenericOptionsParser(getConf(), optionlist);
String[] otherArgs = optionParser.getRemainingArgs();
Job job = new Job(getConf(), "delayOption");
job.setMapperClass(MulitAirMapper.class);
job.setReducerClass(MulitAirReducer2.class);
job.setJarByClass(MulitAirDriver.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
MultipleOutputs.addNamedOutput(job, "dep",
TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "arr",
TextOutputFormat.class, Text.class, IntWritable.class);
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new MulitAirDriver(), args);
}
}
-
jar 파일 export후 build path에 추가
-
있으면 삭제 후 추가

실행

-
결과


'Hadoop' 카테고리의 다른 글
| 빅데이터 플랫폼 구축 #12 - Flume (1) (0) | 2020.10.10 |
|---|---|
| 빅데이터 플랫폼 구축 #11 - Sqoop (0) | 2020.10.10 |
| 빅데이터 플랫폼 구축 #9 - 이클립스에서 namenode 연결, 하둡 사용 (0) | 2020.10.07 |
| 빅데이터 플랫폼 구축 #8 - Mapreduce : 사용자 정의 옵션 활용 (0) | 2020.10.05 |
| 빅데이터 플랫폼 구축 #7 - MapReduce 연습 (0) | 2020.10.04 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- jdbc
- File Protection
- Disk Scheduling
- mapreduce
- 빅데이터
- SQL
- springboot
- gradle
- JSON
- linux
- Spring
- Disk System
- HDFS
- Java
- vmware
- Flume
- maven
- 하둡
- Allocation methods
- aop
- hadoop
- Variable allocation
- oracle
- RAID Architecture
- Free space management
- SPARK
- Replacement Strategies
- I/O Mechanisms
- I/O Services of OS
- 빅데이터 플랫폼
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
글 보관함