
티스토리 뷰
Replacement Strategies
-
Fixed allocation : 프로세스에 고정된 수의 page frame을 할당
- MIN(OPT, B0) algorithm
- Random algorithm
- FIFO(First In First Out) algorithm
- LRU(Least Recently Used) algorithm
- LFU(Least Frequently Used) algorithm
- NUR(Not Used Recently) algorithm
- Clock algorithm
- Second chance algorithm
-
Variable allocation
- WS(Working Set) algorithm
- PFF(Page Fault Frequency) algorithm
- VMIN(Variable MIN) algorithm
Working Set (WS) algorithm
- 1968년 Denning이 제안
- Working set
- Process가 특정 시점에 자주 참조하는 page들의 집합
- 최근 일정시간 동안(∆) 참조된 page들의 집합
- 시간에 따라 변함
- W(t, ∆)
- The working set of a process at time t
- Time interval [t- ∆, t] 동안 참조된 page들의 집합
- ∆: window size, system parameter
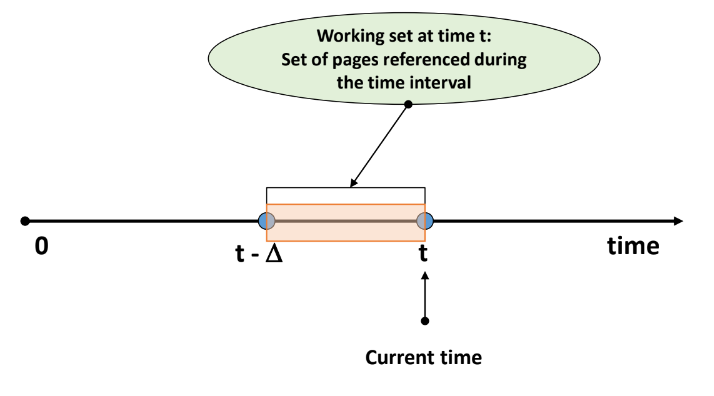
Working set memory management
- Locality에 기반을 둠
- Working set을 메모리에 항상 유지
- Page fault rate (thrashing) 감소
- 시스템 성능 향상
- Window size(∆)는 고정
- Memory allocation은 가변
(Memory allocation 고정, window size가 가변 -> LRU) - ∆ 값이 성능을 결정짓는 중요한 요소
- Memory allocation은 가변
Window size vs. WS size

Example : working set transition

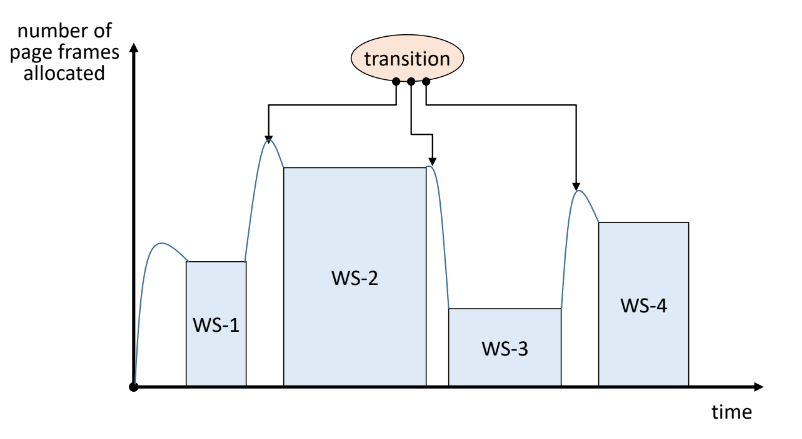
- working set이 변화할 때 두 working set이 모두 참조되어야 하므로 일시적으로 page frame수가 증가한다.
Example
- ∆= 3, number of pages = 5 (0, 1, 2, 3, 4)
- Initially pages {0, 3, 4} in the memory at time 0
- w = 2 2 3 1 2 4 2 4 0 3

- Time 1 : [-2, 1] 동안 참조된 page : 0, 2, 3, 4
-> page 2를 메모리에 올림
-> page frame : 4 - Time 2 : [-1, 2] 동안 참조된 page : 0, 2, 3
-> page 4를 메모리에서 내림
-> page frame : 3 - ...
성능평가
- Page fault 수 외 다른 지표도 함께 봐야 함
- Example
- Time interval [1,10]
- # of page fault = 5
- 평균 할당 page frame 수 = 3.2
- 평가
- 평균 3.2개의 page frame을 할당 받은 상태에서 5번의 page fault 발생
- page fault 를 처리하는 비용과 page frame을 유지하는 비용을 비교하여 성능 평가
- ex. Cost(PF) = 50 , Cost(P) = 10, Time [1,10]
algorithm1 : page fault = 5, 평균 page frame 수 = 3.2
-> 50 * 5 + 3.2 * 10 * 10 = 570
algorithm2 : page fault = 6, 평균 page frame 수 = 2.5
-> 50 * 6 + 2.5 * 10 * 10 = 550
=> algorithm2 > algorithm1
- ex. Cost(PF) = 50 , Cost(P) = 10, Time [1,10]
- Time interval [1,10]
특성
- 적재 되는 page가 없더라도, 메모리를 반납하는 page가 있을 수 있음
- 새로 적재되는 page가 있더라도, 교체되는 page가 없을 수 있음
단점
- Working set management overhead
- Residence set(상주 집합)을 Page fault가 없더라도, 지속적으로 관리해야 함
Mean number of frames allocated VS page fault rate

- window size가 커지면 page lifetime 증가하지만 page유지 비용도 증가
- window size가 커지면 page fault rate 감소
Page Fault Frequency (PFF) algorithm
- Residence set size를 page fault rate에 따라 결정
- Low page fault rate (long inter-fault time)
- Process에게 할당된 PF 수를 감소
- High page fault rate (short inter-fault time)
- Process에게 할당된 PF 수를 증가
- Low page fault rate (long inter-fault time)
- Residence set 갱신 및 메모리 할당
- page fault가 발생시에만 수행
- Low overhead
- Criteria for page fault rate
- IFT : page fault 사이의 시간
- IFT > τ : Low page fault rate
- IFT < τ : High page fault
- τ : threshold value
- System parameter
algorithm
- Page fault 발생 시, IFT계산
- IFT = tc − tc-1
- tc-1 : time of previous page fault
- tc : time of current page fault
- IFT = tc − tc-1
- IFT > τ (Low page fault rate)
- Residence set <ㅡ (tc-1,tc] 동안 참조된 page 들 만 유지
- 나머지 page 들은 메모리에서 내림
- 메모리 할당(#of page frames) 유지 or 감소
- IFT ≤ τ (High page fault rate)
- 기존 pages 들 유지
- + 현재 참조된 page 를 추가 적재
- 메모리 할당(# of page frames) 증가
Example
- τ=2, number of pages = 5 (0, 1, 2, 3, 4)
- Initially pages {0, 3, 4} in the memory at time 0
- w = 2 2 3 1 2 4 2 4 0 3

- Time 1 : IFT = 1 - 0 = 1 < τ(=2) 이므로 page frame 증가( 3 -> 4 )
page 2 메모리에 올림 - Time 4 : IFT = 4 - 1 = 3 > τ(=2) 이므로 page frame 감소( 4 -> 3 )
(1, 4] 에 참조된 페이지 : 1,2,3
0, 4 페이지 메모리에 내려옴, 1 페이지 메모리 올림 - Time 6 : IFT = 6 - 4 = 2 = τ(=2) 이므로 page frame 증가( 3 -> 4 )
page 4 메모리에 올림 - ...
성능평가
- Page fault 수 외 다른 지표도 함께 봐야 함
- Example
- Time interval [1,10]
- # of page fault = 5
- 평균 할당 page frame = 3.7
- 평가
- 평균 3.7개의 page frame을 할당받은 상태에서 5번의 page fault 발생
- Time interval [1,10]
특징
- 메모리 상태 변화가 page fault 발생 시에만 변함
-> Low overhead
Variable MIN (VMIN) algorithm
- Variable allocation 기반 교체 기법 중 optimal algorithm
- 평균 메모리 할당량과 page fault 발생 횟수 모두 고려했을 때의 Optimal
- 실현 불가능한 기법 (Unrealizable)
- Page reference string 을 미리 알고 있어야 함
- 기법
- [t,t + ∆] 을 고려해서 교체할 page 선택
Algorithm
- Page r이 t시간에 참조 되면 , page r (t,t + ∆] 사이에 다시 참조되는지 확인
- 참조 된다면, page r을 유지
- 참조 되지 않는다면, page r을 메모리에서 내림
Example
- ∆=4, number of pages = 5 (0, 1, 2, 3, 4)
- w = 2 2 3 1 2 4 2 4 0 3

- Time 0 : (0, 4] 사이에 3을 참조 하고 있으므로 유지
- Time 1 : (1, 5] 사이에 2를 참조 하고 있으므로 유지
- ...
- Time 3 : (3, 7] 사이에 3이 참조되고 있지 않으므로 메모리에서 내린다.
- ...
성능평가
- Page fault 수 외 다른 지표도 함께 봐야 함
- Example
- Time interval [1,10]
- # of page fault = 5
- 평균 할당 page frame = 1.6
- 평가
- 평균 1.6개의 page frame을 할당받은 상태에서 5번의 page fault 발생
- Time interval [1,10]
최적 성능을 위한 ∆값은?
- ∆= R / U
• U: 한번의 참조 시간 동안 page를 메모리에 유지하는 비용
• R: page fault 발생 시 처리 비용 - R > ∆ ∗ U, (∆ 가 작으면)
• 처리 비용 > page 유지비용 - R < ∆ ∗ U, (∆ 가 크면)
• page fault 처리 비용 < 유지비용
Other Considerations
- Page size
- Program restructuring
- TLB reach
Page Size
- 시스템 특성에 따라 다름
- No best answer
- 점점 커지는 경향
- 일반적인 page size
- 2^7 (128) bytes ~ 2^22 (4M) bytes
| 일반적인 특성 | |
| Small page size | Large page size |
| Large page table / # of PF -> High overhead (kernel) |
Small page table / # of PF -> Low overhead (kernel) |
| 내부 단편화 감소 | 내부 단편화 증가 |
| I/O 시간 증가 | I/O 시간 감소 |
| Locality 향상 | Locality 저하 |
| Page fault 증가 | Page fault 감소 |
| [HW 발전 경향] CPU 성능 증가, Memory size 성능 증가( CPU가 disk보다 빠르게 발전) => 상대적으로 Page fault 처리비용이 높다. => 따라서 page size가 커지는 경향이 있다. |
|
Program Restructuring
- 가상 메모리 시스템의 특성에 맞도록 프로그램을 재구성
- 사용자가 가상 메모리 관리 기법(예, paging system)에 대해 이해하고 있다면, 프로그램의 구조를 변경하여 성능을 높일 수 있음
Example
- Paging system, Page size = 1 KB
- sizeof(int) = 4 bytes
- page frame = 1

- 2차원 배열 zar의 행 하나가 1page ( 256 * 4bytes = 1KB )
- Row-major order for array


| program-1 | program-2 |
| w = 0 1 2 3 ... 255 0 1 2 ... 루프가 돌때마다 매번 page fault가 일어난다. => 256 * 256 = 65536 |
w = 0 0 0 ... 0 1 1 1 ... 1 2 2 .... 행이 전환 될 때만 page fault 가 일어난다. => 256 |
TLB Reach
- TLB : Translation Lookaside Buffer
가상 메모리 주소를 물리적인 주소로 변환하는 속도를 높이기 위해 사용되는 캐시 - TLB를 통해 접근 할 수 있는 메모리의 양
- (The number of entries) * (the page size)
- TLB Reach가 크다 -> 접근할수 있는 범위가 넓다 -> hit ratio 증가
- TLB의 hit ratio를 높이려면
- TLB의 크기 증가 -> expensive
- Page 크기 증가 , 다양한 page size 지원
-> OS의 지원이 필요
가상메모리 관리 Summary
- Virtual memory management
- Cost model
- Hardware components
- Software components
- Page replacement schemes
- FA-based schemes
- VA-based schemes
- Other considerations
강의
www.youtube.com/watch?v=ByQmerWj1bg&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=36
www.youtube.com/watch?v=_QpNwu_MYck&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=37
'운영체제' 카테고리의 다른 글
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- aop
- jdbc
- I/O Services of OS
- oracle
- mapreduce
- 빅데이터
- 빅데이터 플랫폼
- Variable allocation
- Disk Scheduling
- RAID Architecture
- Allocation methods
- maven
- Flume
- Free space management
- Disk System
- JSON
- SQL
- linux
- 하둡
- gradle
- Replacement Strategies
- Java
- SPARK
- hadoop
- Spring
- springboot
- vmware
- HDFS
- File Protection
- I/O Mechanisms
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함