
티스토리 뷰
Multi Node Cluster( 완전 분산 모드)
-
master, worker1, worker2 실행
-
도메인 설정( master, worker1, worker2 모두 설정)

-
hostname으로 ping 확인



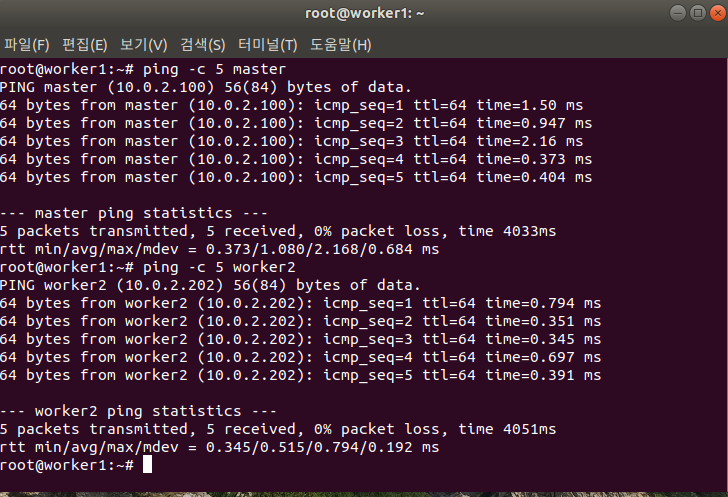
-
NFS 설정 추가(master)




-
nfs서버 재시작

-
nfs서버 mount(worker1, worker2)






-
ssh 설정 ( master, worker1, worker2)

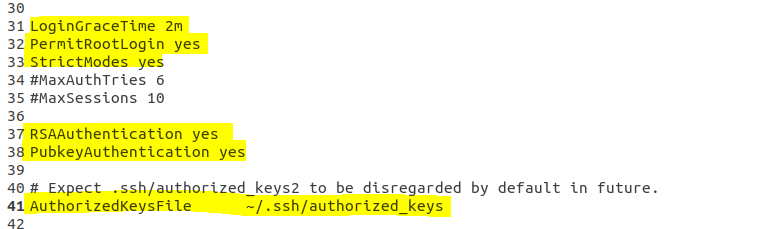
-
ssh restart

-
공개키 생성
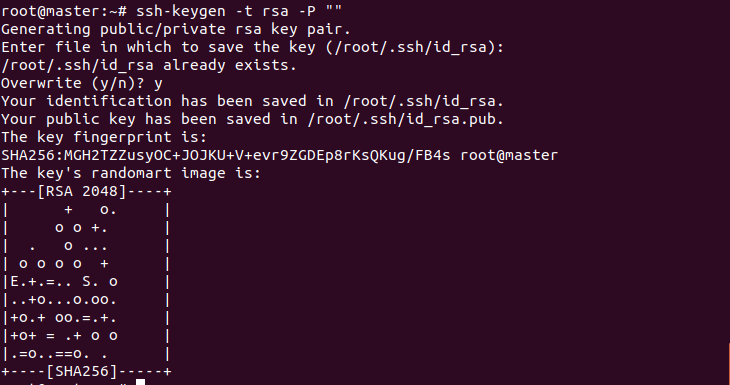

-
worker1
-
ssh 서버 설치

-
master 와 같이 설정




-
worker2
-
ssh 서버 설치

-
master 와 같이 설정




-
key 복사
-
하둡은 각 노드에서 데이터를 처리한 후 재조합 하여 다시 분석을 한다. 노드간 데이터 이동 시 보안을 위해 ssh 를 사용. 노드 이동을 위해 키 값들을 각 노드에 복사한다.
master -> worker1

master -> worker2

worker1 -> master

worker1 -> worker2

worker2 -> master

worker2 -> worker1

-
복사한 key 추가



-
각 노드별 ssh 접속 확인
-
ssh (노드 이름)

하둡 설정
-
master




-
worker1, worker2 하둡 설치

-
설정






-
설치 확인

-
노드 설정
-
master는 namenode, datanode 생성
-
worker는 datanode만 생성





-
하둡 설정
-
master


worker1, worker2



-
잡트래커 설정 ( master, worker1, worker2 )




-
마스터, 워커 설정
-
master, worker1, worker2 모두 세팅


-
master, worker1, worker2 모두 세팅




-
권한 설정 (master, worker1, worker2)

-
포맷 전 하둡 종료

-
포맷

-
실행 확인

< worker1 >

< worker2 >

-
DataNode 가 올라오지 않는 경우
-
yarn, hadoop을 끄고 재설정

-
datanode 를 지우고 다시 설정

-
하둡 안에 input , output 폴더 생성

-
분석 데이터 input에 올림
-
하둡은 대량의 데이터 분석에 적합, 소량의 데이터 분석은 오히려 느릴 수 있다.

-
확인

-
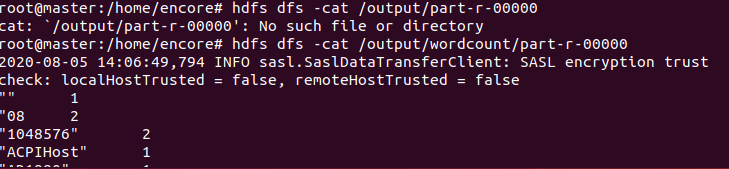
wordcount 분석

-
결과 확인

-
폴더로 결과 복사
-
같은 폴더 이름이 있으면 분석하지 않고 종료 하므로 결과파일을 복사하고 하둡의 output/wordcount 폴더는 지운다

-
에러 발생 시

-
start-yarn.sh 로 실행하면 오류발생
-
yarn을 개별적으로 실행하면 해결


wordcount 만들기 (이클립스)
-
이클립스에서 하둡의 jar 파일을 사용하기 위해 파일 복사

-
이클립스 프로젝트에 추가

-
외부 jar 파일 인식


-
Java 프로젝트

< MyMapper.java >
package count;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// IN 1, read a book
// OUT <read,1> <a,1> <book,1>
private static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokens = new StringTokenizer(value.toString());
while(tokens.hasMoreTokens()){
word.set(tokens.nextToken());
context.write(word, one);
}
}
}
< MyReducer.java >
package count;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
// IN <read,1> <a,1> <book,1>
// <write,1> <a,1> <book,1>
// OUT <read,1> <a,2> <book,2>
IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val : value) {
sum += val.get(); // +1
}
result.set(sum);
context.write(key, result);
}
}< WordCount.java >
package count;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
// IN <read,1> <a,1> <book,1>
// <write,1> <a,1> <book,1>
// OUT <read,1> <a,2> <book,2>
private int sum = 0;
IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
for(IntWritable val : value) {
sum += val.get(); // +1
}
result.set(sum);
context.write(key, result);
}
}
-
JAR 파일 생성


-
실행

-
결과 확인

- Total
- Today
- Yesterday
- RAID Architecture
- Variable allocation
- hadoop
- 빅데이터 플랫폼
- I/O Mechanisms
- gradle
- Spring
- JSON
- SPARK
- I/O Services of OS
- Free space management
- Disk System
- Replacement Strategies
- jdbc
- 빅데이터
- oracle
- Java
- springboot
- mapreduce
- Flume
- Disk Scheduling
- Allocation methods
- aop
- 하둡
- SQL
- HDFS
- linux
- File Protection
- maven
- vmware
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |