
티스토리 뷰
-
문자열, 수치 등을 관리하는 기본 자료형
-
종류 : String, Tuples, Lists
-
배열 형식 : 문자열, 수치 등을 나열해서 관리하는 배열형식을 가진다.
-
인덱싱 : 배열로 저장된 형식을 취하기 때문에 인덱싱을 이용하여 저장된 자료의 위치를 참조해서 활용할 수 있다.
-
슬라이싱 : 특정 구간의 자료를 리턴할 수 있는 슬라이싱 기능
-
연결과 반복 : +, * 를 통해 자료를 연결하거나 반복 가능
-
자료 확인 : in 키워드를 통해 어떤 값이 시퀀스 자료에 속해 있는지 확인
String
-
문자열의 인덱싱

-
문자열의 슬라이싱
-
[인덱스 시작 : 인덱스 끝 : 스텝]

-
슬라이싱은 원본의 데이터를 복사해 오기때문에 복사해온 데이터를 바꿔도 원본은 바뀌지 않는다.

-
문자열은 immutable 이므로 중간의 데이터를 바꿀 수 없다.

-
문자열 반복과 합치기

-
formating

-
range 함수
-
파이썬 3에서는 range함수가 lazy 방식 -> list 나 tuple 등 으로 만들어야만 메모리 할당을 함.
-
range(end) : 0 ~ end-1 까지 값을 나열
-
range(start, end) : start 부터 end-1 까지 값을 나열
-
range(start, end, step) : start 부터 end-1 까지 step씩 건너뜀


-
내장 함수들
-
upper() : 대문자로 변경
-
lower() : 소문자로 변경
-
swapcase() : 대문자 -> 소문자 , 소문자 -> 대문자

-
count() : 문자열 횟수
-
find() : 문자열의 첫 글자 위치 리턴

-
split - 문자열 분할

-
join - 문자열 합치기

-
splitlines - 라인단위로 분할
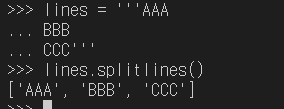
-
center, just - 정렬

-
공백에 채워질 문자를 지정할 수 있다.

-
공백을 숫자 0 으로 채우기

튜플(Tuple)
-
( ) 안에 요소를 나열
-
숫자와 문자를 함께 관리
-
immutable type 으로 값을 변경할 수 없다.
-
튜플의 인덱싱
-
기본 튜플 - 빈 튜플
-
혼합형 튜플 - 모든 객체가 원소로 올 수 있다.
-
nested 튜플 - 튜플 안에 튜플
-

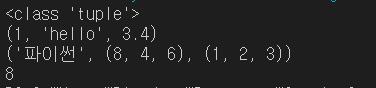

-
튜플의 원소는 바꿀 수 없지만 튜플 안의 리스트는 바꿀 수 있다

-
또 다른 튜플 생성 방법
-
, 로 나열된 데이터는 튜플로 인식

-
튜플의 슬라이싱 - 문자열 슬라이싱과 같다
-
튜플을 슬라이싱 하면 튜플이 나온다.

-
튜플의 병합과 반복

-
index(x) - 튜플에서 첫번째 x 값을 찾아서 그 위치 리턴
-
count(x) - 튜플에서 x 가 몇개 있는지 리턴
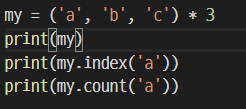

리스트(list)
-
[] 안에 나열된 데이터 들을 저장 및 관리
-
mutable type 으로 값을 수정할 수 있다
-
리스트의 인덱싱
-
기본 리스트 - 빈 리스트
-
혼합형 리스트
-
매트릭스 리스트
-


-
리스트 슬라이싱
-
시퀀스의 기본 규칙에 따라 대괄호 안에 슬라이싱 하고자 하는 인덱스를 [start : end : step] 순서로 지정해서 값을 리턴
-
in , not in
-
리스트에 요소가 포함되어있는지 확인
my = ['a', 'b', [3.58, 'd', 4, 0]]
# 'b'가 리스트에 있는지 유무를 리턴
print('b' in my)
# 'e'가 리스트에 없는지 유무를 리턴
print('e' not in my)
# 'd'가 my[2] 에 있는지 유무를 리턴
print('d' in my[2])
-
리스트 내장함수
| 함수 | 설명 |
| cmp(list1, list2) | list를 비교해서 리턴 |
| len(list) | 리스트의 크기(요소의 개수) 리턴 |
| max(list) | 리스트에서 가장 큰 값 리턴 |
| min(list) | 리스트에서 가장 작은 값 리턴 |
| list.append(obj) | list에 obj 추가 |
| list.count(obj) | list에 obj의 개수를 리턴 |
| list.extend(seq) | list에 seq를 추가 |
| list.index(obj) | obj의 인덱스 값 리턴 |
| list.insert(index, obj) | list의 index위치에 obj 삽입 |
| list.pop() | list의 마지막 요소 제거 |
| list.remove(obj) | list에서 obj를 제거 |
| list.reverse() | list를 역순으로 재배치 |
| list.sort() | list를 정렬 |
val = [10, 20, 20, 30, 40, 50]
print(val)
# 자료 값 10 삭제
val.remove(10)
print(val)
# 같은 자료 값이 여러 개 존재하면 첫 번째 것만 삭제
val.remove(20)
print(val)
# 역순으로 리턴
val.reverse()
print(val)
# 마지막 요소를 리턴 후 제거
print(val.pop())
# 길이 리턴
print(len(val))
val = [10, 20, 30, 40, 50]
# 새로운 리스트를 기존 리스트 뒤에 병합
val.extend([60, 70])
print(val)
# append로 추가시 하나의 리스트 요소로 추가
val.append([80, 90])
print(val)
# 원하는 위치에 삽입
val.insert(2, ('a', 'b'))
print(val)
my = ['cat', 'rat', 'dog', 'money']
print(my)
# 값 수정
my[0] = 'puppy'
print(my)
# 객체 삭제
del my[0]
print(my)
# 요소 삭제
my.remove('rat')
print(my)
# 객체 추가
my.append((10, 20, 30))
print(my)
# 값으로 삭제
my.remove((10, 20, 30))
print(my)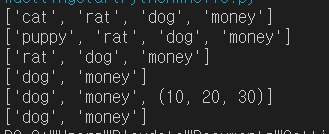
'Python' 카테고리의 다른 글
| 정규표현식 (0) | 2020.08.26 |
|---|---|
| 표준 입력과 출력 (0) | 2020.08.26 |
| Dictionary & Set (0) | 2020.08.26 |
| 기본 자료형과 연산자 (0) | 2020.08.19 |
| 파이썬 설치 (0) | 2020.08.19 |
- Total
- Today
- Yesterday
- Variable allocation
- hadoop
- Disk System
- I/O Mechanisms
- jdbc
- Replacement Strategies
- Disk Scheduling
- Free space management
- gradle
- 빅데이터 플랫폼
- 빅데이터
- Spring
- HDFS
- Java
- I/O Services of OS
- Flume
- linux
- maven
- SQL
- aop
- File Protection
- JSON
- Allocation methods
- vmware
- 하둡
- oracle
- SPARK
- mapreduce
- RAID Architecture
- springboot
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |