
티스토리 뷰
정규표현식
파이썬의 정규식(Regular Expressions)
-
정규식은 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식언어를 말한다.
-
주어진 패턴으로 문자열을 검색 및 치환하는 데 사용
-
정규표현식을 위하여 re모듈을 사용
| 메타문자 | 설명 |
| . | 개행 문자를 제외한 문자 1자와 매치됨. <br />re.DOTALL이 설정되어 있으면, 개행을 포함한 문자 1자를 나타냄. |
| ^ | 문자열의 시작과 매치됨<br />re.MULTILINE이 설정되어 있으면 매라인 마다 매치됨. |
| $ | 문자열의 마지막과 매치됨<br />re.MULTILINE이 설정되어 있으면 매라인 마다 매치됨. |
| [] | 문자의 집합을 나타냄<br />[abcd]의 경우 'a', 'b', 'c', 'd' 중 한 문자와 매치됨. |
| \| | 'A\|B'와 같은 경우 'A' 혹은 'B'를 나타냄(OR연산) |
| () | 괄호 안의 정규식으로 그룹을 만듦.<br />직접'(', ')'(괄호)를 매치시키기 위하여 '\\(', '\\)'나 '[(]','[)]'로 나타냄. |
| * | 문자가 0회 이상 반복됨을 나타냄 |
| + | 문자가 1회 이상 반복됨을 나타냄 |
| ? | 문자가 0회 혹은 1회 반복됨을 나타냄 |
| {m} | 문자가 m회 반복됨을 나타냄 |
| {m,n} | 문자가 m회 부터 n회 까지 반복되는 모든 경우를 나타냄 |
| {m,} | 문자가 m회 부터 무한 반복되는 모든 경우를 나타냄 |
'bana.a' -> abanana, bananna, bana!a, bana a ...
'^banana' -> banana1, banana2, banana abc ...
'banan[a-z]' -> banana, bananb, ... , bananzre 모듈
| 함수명 | 설명 |
| re.search(pattern, string[,flags]) | string전체에 대해서 pattern이 존재하는지 검사하여 MatchObject인스턴스를 반환 |
| re.match(pattern, string[,flags]) | string시작부분부터 pattern이 존재하는지 검사하여 MatchObject인스턴스를 반환 |
| re.split(pattern, string[,maxsplit=0]) | pattern을 구분자로 string을 분리하여 리스트로 반환 |
| re.findall(pattern, string[,flags]) | string에서 pattern과 매치되는 모든 경우를 찾아 리스트로 반환 |
| re.finditer(pattern, string[,flags]) | string에서 pattern과 일치하는 결과에 대한 이터레이터 객체를 반환 |
| re.sub(pattern, repl, string[,count]) | string에서 pattern과 일치하는 부분에 대하여 repl로 교체하여 결과 문자열을 반환함 |
| re.subn(pattern, repl, string[,count]) | re.sub()함수와 동일하게 동작하나, 결과(결과문,매칭횟수)를 튜플로 반환 |
| re.escape(string) | 영문자, 숫자가 아닌 문자에 대하여 백슬러시 문자를 추가함.메타문자를 포함한 문자열을 정규식으로 변경할수 있음. |
| re.compile(pattern,[flags]) | pattern을 컴파일하여 '정규표현식 객체(regular expression object)'를 반환함 |
re 모듈 함수 ( match, search )
-
match 객체
-
match() 와 search() 의 수행 결과로 생성
| 메소드 | 내용 |
| group([group1,...]) | 입력받은 인덱스에 해당하는 매칭된 문자열 결과의 부분 집합을 반환인덱스가 '0'이거나 입력되지 않은 경우 전체 매칭문자열을 반환 |
| groups() | 매칭된 결과를 튜플형태로 반환 |
| groupdict() | 이름이 붙어진 매칭결과를 사전형태로 반환 |
| start([group]) | 매칭된 결과 문자열의 시작 인덱스를 반환인자로 부분 집합의 번호나 명시된 이름이 전달된 경우,그에 해당하는 시작 인덱스를 반환 |
| end([group]) | 매칭된 결과 문자열의 종료 인덱스를 반환인자로 부분 집합의 번호나 명시된 이름이 전달된 경우,그에 해당하는 종료인덱스를 반환 |
| 속성 | 내용 |
| pos | 원본 문자열에서 검색을 시작하는 위치 |
| endpos | 원본 문자열에서 검색을 종료하는 위치 |
| lastindex | 매칭된 결과 집합에서 마지막 인덱스 번호를 반환일치된 결과가 없는 경우 None을 반환 |
| lastgroup | 매칭된 결과 집합에서 마지막으로 일치한 이름을 반환정규식의 매칭조건에 이름이 지정되지 않았거나일치된 결과가 없는 경우에는 None을 반환 |
| string | 매칭의 대상이 되는 원본문자열 |
import re
m_str = 'matches the start of a string.'
print(re.search('.', '\n'))
print(re.search('.', m_str))
m = re.match('[a-z]+', m_str)
print(m.group())
r = re.search('[a-z]+', m_str)
print(r.group())
import re
str = '!wow, so hot'
m = re.match('[a-z]+', str)
print(m)
r = re.search('[a-z]+', str)
print(r.group())
-
이스케이프 문자열
| 종류 | 설명 |
| \W | 유니코드인 경우 숫자, 밑줄과 표현 가능한 문자를 제외한 나머지 문자,아스키코드인 경우 '[^a-zA-Z0-9_]'와 동일함 |
| \d | 유니코드인 경우 [0-9]를 포함하는 모든 숫자임.아스키코드인 경우 [0-9]와 동일함 |
| \D | 유니코드인 경우 숫자를 제외한 모든 문자아스키코드인경우 [^0-9]와 동일함 |
| \s | 유니코드인경우 [\t\n\r\f\v]를 포함하는 공백문자아스키코드인경우 [\t\n\r\f\v]와 동일함 |
| \S | 유니코드인 경우 공백문자를 제외한 모든 문자아스키코드인경우 [^\t\n\r\f\v]와 동일함 |
| \b | 단어의 시작과 끝의 빈공백 |
| \B | 단어의 시작과 끝이 아닌 빈공백 |
| \\ | 역슬래시(\) 문자 자체를 의미 |
| \[숫자] | 지정된 숫자만큼 일치하는 문자열을 의미 |
| \A | 문자열의 시작 |
| \Z | 문자열의 끝 |
| \w | 유니코드인 경우 숫자, 밑줄(underscore, '_')를 포함하는 모든 언어의 표현 가능한 문자,아스키코드인 경우 '[a-zA-Z0-9_]'와 동일함 |
# \ 로 시작하는 아무 문자 찾기
import re
r = bool(re.search('\\\\\w+', '\\banana'))
print(r)
# 앞에 r 을 쓰면 그 뒤는 모두 문자로 인식
r1 = bool(re.search(r'\\\w+', r'\banana'))
print(r1)
import re
a = re.search(r'\d+', 'abcd0123efgh')
print(a)
print(a.group())
print(a.start(), a.end())
re 모듈 함수 ( findall, sub )
-
findall
-
패턴과 매칭되는 모든 경우를 찾아 리스트로 리턴
import re
# * , + 의 차이
res = re.findall('a\w*', 'application a orange apple banana')
res1 = re.findall('a\w+', 'application a orange apple banana')
print(res)
print(res1)
-
sub
-
패턴과 일치하는 문자열을 변경
import re
# 형식을 변경
res = re.sub('-', ',', '123-456-789')
print(res)
# 구분자 통일
res1 = re.sub(r'[:|]', ',','a:b|c')
print(res1)
# 변경회수 제한
res2 = re.sub('[:,|\s]','_','one:two three/four',2)
print(res2)
re.compile(pattern, [flags])
-
자주 사용하는 패턴을 등록해서 사용
| 클래스 | 설명 |
| re.I(대문자 아이)re.IGNORECASE | 대소문자를 구분하지 않고 매칭작업을 수행 |
| re.Mre.MULTILINE | 문자열이 여러줄인경우, 이 플래그가 설정되면'^'는 각 행의 처음을 나타내고'$'는 각 행의 마지막을 나타냄기본값은 '^'는 문자열의 첫행의 처음을,'$'는 마지막행의 마지막만을 나타냄 |
| re.Sre.DOTALL | 이 플래그가 설정되면 개행 문자도 '.'으로 매칭됨기본값은 '.'은 개행문자와 매칭되지 않는다. |
| re.Xre.VERBOSE | 정규표현식을 보기 쉽게 작성할수 있다.정규표현식에서 '#'으로 시작하는 파이썬 주석과 빈 공백은 무시된다.빈 공백을 표현하기 위해서는 '\ '으로 표현해야 한다. |
| re.Are.ASCII | 이 플래그가 설정되면 '\w, '\W', '\b', '\B', '\s', '\S'는 유니코드대신에 아스키코드만 매칭됨 |
| re.Lre.LOCALE | 이 플래그가 설정되면 '\w, '\W', '\b', '\B', '\s', '\S' 는 현재 로케일 설정을 따른다.파이썬3버전부터 기본적으로 유니코드가 사용되기 때문에 자주 사용되지는 않는다. |
import re
s = ('grape orange apple banana GRAPE')
c = re.compile('grape',re.I) # 대소문자 구분하지 않음
print(c)
res = c.findall(s)
print(res)
import re
c = re.compile(r'app\w*') # 패턴 등록
res = c.findall('application orange apple banana') # 검색
print(res)
pat = re.compile(r'\w+') # 패턴등록
res1 = pat.findall('puppy duck cat') # 검색
print(res1)
# 문자와 숫자 사이에 공백이 있는 패턴 검색
# 괄호로 묶여 있어서 각각 튜플의 원소로 출력
pat = re.compile(r'(\w+)\s+(\d+)') # 패턴등록
res2 = pat.findall('puppy 10 duck 20 cat 30') # 검색
print(res2)
import re
# 숫자-숫자-숫자 패턴 검색
p = re.compile(r'(\d+)-(\d+)-(\d+)')
a = p.search('2018-12-25')
result = a.groups()
print('result : {}'.format(result))
# 그룹을 각각 나누어 리턴
year, month, day = a.groups()
print('year: {}, month: {}, day: {}'.format(year, month, day))
print(a.group(1), a.group(2), a.group(3))

-
정규식 확장 기법
| 표기법 | 설명 |
| (? : ...) | 정규 표현식을 그룹화하여 일치하는 문자열 제외 |
| (? =...) | 정규 표현식 위치 지정 |
| (?! ...) | 정규 표현식의 부정에 의한 위치 지정 |
| (? P \<name> ...) | 그룹 이름 name을 지정 |
| (? P = name) | 그룹 name을 지정해서 참조 |
import re
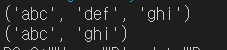
p = re.compile(r'(\w+)\s+(\w+)\s+(\w+)')
a = p.search('abc def ghi')
print(a)
# 그룹화 하지만 ?: 가 있는 문자열은 저장하지 않는다.
p = re.compile(r'(\w+)\s+(?:\w+)\s+(\w+)')
a = p.search( 'abc def ghi')
print(a)
import re
# 패턴 문자열의 이름을 지정
p = re.compile(r'(?P<word>\w+)\s+(?P=word)')
a = p.search('python python')
print(a.group('word'))
print(a.group(1))
# 패턴에서 뒤의 문자열이 java 일때만 검색
p = re.compile(r'python\s+(?=java)')
a = p.search('python java')
print(a.group())
# 패턴에서 뒤의 문자열이 java가 아닐 때 검색
q = re.compile(r'python\s+(?!java)')
b = q.search('python jav')
print(b.group())
import re
my_str = 'My mobile phone number is 010-123-4567'
MPattern = re.compile(r'(\d{3})-(\d{3})-(\d{4})')
Mres = MPattern.search(my_str).groups()
print(Mres)
print(re.sub(' ', ':', my_str, 5))
'Python' 카테고리의 다른 글
| 함수 - 파라미터, 람다함수, 고차함수, 재귀함수, 스코핑룰 (0) | 2020.08.28 |
|---|---|
| 제어문 - 조건문, 반복문, 흐름 제어문 (0) | 2020.08.28 |
| 표준 입력과 출력 (0) | 2020.08.26 |
| Dictionary & Set (0) | 2020.08.26 |
| Sequences (0) | 2020.08.19 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- gradle
- Free space management
- Replacement Strategies
- HDFS
- springboot
- 하둡
- SQL
- JSON
- linux
- maven
- Spring
- hadoop
- Disk Scheduling
- SPARK
- Java
- Allocation methods
- File Protection
- vmware
- I/O Services of OS
- 빅데이터
- aop
- Disk System
- jdbc
- Flume
- 빅데이터 플랫폼
- RAID Architecture
- I/O Mechanisms
- mapreduce
- Variable allocation
- oracle
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함