
티스토리 뷰
- 파이참 프로젝트 생성

- File -> Setting -> Project -> python Interpreter

- 패키지 다운로드 : dload -> url을 통해 이미지를 다운받는 패키지

- dload 사용 (괄호 안에 이미지 주소)
import dload
dload.save("http://cafefiles.naver.net/20120810_284/pink_racer_1344579252729LEcJW_JPEG/%B0%ED%BE%E7%C0%CC_%C1%BE%B7%F9_%BE%C6%B8%DE%B8%AE%C4%AB_%BC%F4%C7%EC%BE%EE.jpg")- 실행 하면 자동으로 이미지 다운로드

- 셀레니움 설치

- 크롬 버전 확인

- 웹드라이버 설치
chromedriver.storage.googleapis.com/index.html
https://chromedriver.storage.googleapis.com/index.html
chromedriver.storage.googleapis.com
- selenium 사용
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
driver.get("http://www.naver.com")네이버로 이동

- beautifulSoup 다운

- 크롤링 시작하기
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=%EA%B3%A0%EC%96%91%EC%9D%B4&oquery=%EA%B3%A0%EC%96%91%EC%9D%B4&tqi=U3TRplprvxZsslJZfcKssssst7Z-232939")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기
req = driver.page_source
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(req, 'html.parser')
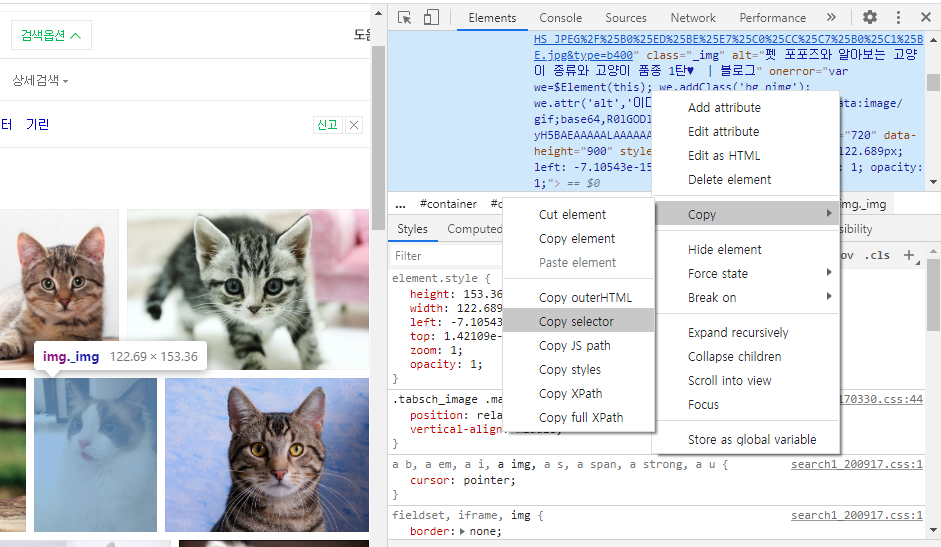
thumbnail = soup.select_one('#_sau_imageTab > div.photowall._photoGridWrapper > div.photo_grid._box > div:nth-child(8) > a.thumb._thumb > img')['src']
print(thumbnail)
driver.quit() # 끝나면 닫아주기- 이미지 경로 추출

- 여러개 가져오기
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=%EA%B3%A0%EC%96%91%EC%9D%B4&oquery=%EA%B3%A0%EC%96%91%EC%9D%B4&tqi=U3TRplprvxZsslJZfcKssssst7Z-232939")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기
req = driver.page_source
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(req, 'html.parser')
thumbnails = soup.select('#_sau_imageTab > div.photowall._photoGridWrapper > div.photo_grid._box > div > a.thumb._thumb > img')
for thumbnail in thumbnails:
img = thumbnail['src']
print(img)
driver.quit() # 끝나면 닫아주기
- 사진 다운로드
import dload
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query=%EA%B3%A0%EC%96%91%EC%9D%B4&oquery=%EA%B3%A0%EC%96%91%EC%9D%B4&tqi=U3TRplprvxZsslJZfcKssssst7Z-232939")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기
req = driver.page_source
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(req, 'html.parser')
thumbnails = soup.select('#_sau_imageTab > div.photowall._photoGridWrapper > div > div > a.thumb._thumb > img')
i = 1
for thumbnail in thumbnails:
img = thumbnail['src']
dload.save(img, f'images/{i}.jpg')
i += 1
driver.quit() # 끝나면 닫아주기
'Python' 카테고리의 다른 글
| 이미지 웹 스크래핑 & 크롤링 #3 - 이메일 보내기 (0) | 2020.10.02 |
|---|---|
| 이미지 웹 스크래핑 & 크롤링 #2 - 뉴스 기사 가져와서 엑셀로 저장하기 (0) | 2020.10.02 |
| 웹 어플리케이션 (0) | 2020.08.29 |
| 네트워크 (0) | 2020.08.29 |
| 쓰레딩(Threading (0) | 2020.08.29 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- linux
- 빅데이터 플랫폼
- SQL
- 빅데이터
- Replacement Strategies
- Variable allocation
- 하둡
- Allocation methods
- Free space management
- Disk Scheduling
- springboot
- Java
- Flume
- mapreduce
- gradle
- hadoop
- jdbc
- oracle
- vmware
- RAID Architecture
- maven
- SPARK
- File Protection
- JSON
- I/O Mechanisms
- Disk System
- HDFS
- Spring
- aop
- I/O Services of OS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함