
티스토리 뷰
네이버 뉴스 가져오기 : 추석 검색 후 뉴스 기사 제목 가져오기
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "가져올 페이지 url 입력"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
articles = soup.select_one("copy selector로 가져온 selector정보")
print(articles.text)
driver.quit()

- 실행

뉴스 기사 여러개 가져오기
- 각 뉴스들은 li태그 안에 있고 그 위에 ul 태그를 가져온다.

- 기사 제목에 관한 정보는 가져온 ul > dl > dt > a 태그에 있다.

from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%B6%94%EC%84%9D"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# ul태그 정보안의 각 기사 정보 가져오기
articles = soup.select("#main_pack > div.news.section._prs_nws_all > ul > li")
# 각 기사의 제목 정보 가져오기
for article in articles:
title = article.select_one('dl > dt > a')
print(title.text) # 기사 제목
driver.quit()- 결과

뉴스의 url가져오기
- 뉴스의 url은 a 태그 안에 href 속성에 있다.

from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%B6%94%EC%84%9D"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# ul태그 정보안의 각 기사 정보 가져오기
articles = soup.select("#main_pack > div.news.section._prs_nws_all > ul > li")
# 각 기사의 제목 정보 가져오기
for article in articles:
title = article.select_one('dl > dt > a')
url = article.select_one('dl > dt > a')['href'] # url
print(title.text, url) # 기사 제목
driver.quit()- 결과

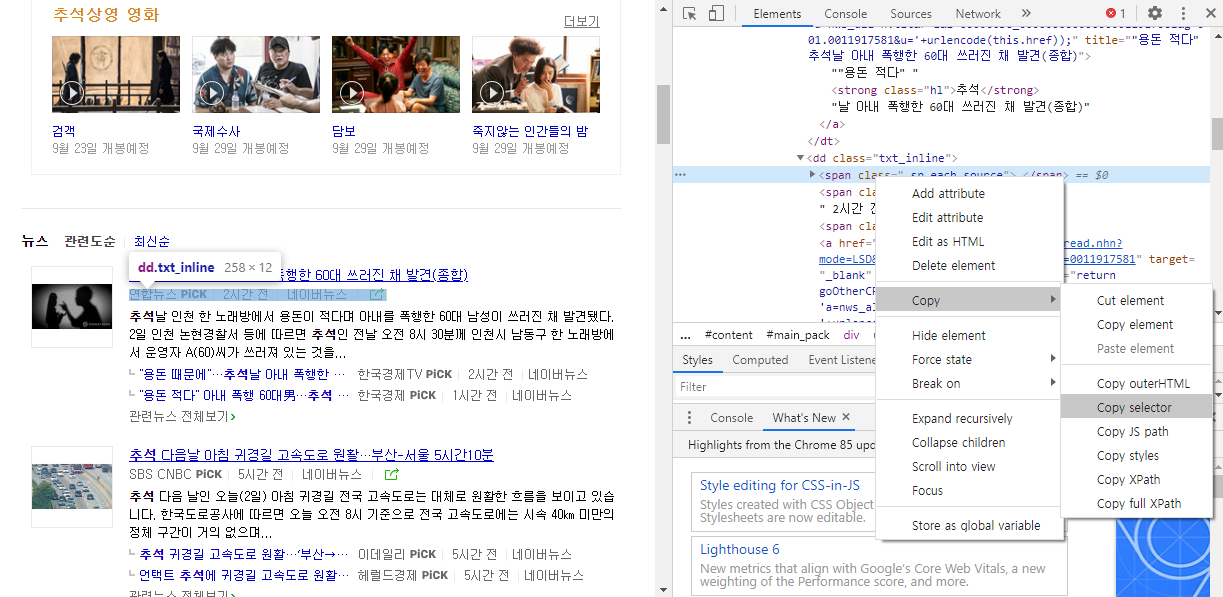
언론사 명 가져오기
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%B6%94%EC%84%9D"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# ul태그 정보안의 각 기사 정보 가져오기
articles = soup.select("#main_pack > div.news.section._prs_nws_all > ul > li")
# 각 기사의 제목 정보 가져오기
for article in articles:
title = article.select_one('dl > dt > a')
url = article.select_one('dl > dt > a')['href'] # url
comp = article.select_one('span._sp_each_source').text
print(comp)
driver.quit()- 실행

- 언론사 명만 가져오기
- 공백으로 split -> 언론사는 공백으로 변환
comp = article.select_one('span._sp_each_source').text.split(' ')[0].replace('언론사', '')
- 결과

엑셀로 저장하기
- openpyxl 패키지 설치

- 사용해보기
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.active
ws1.title = "articles"
ws1.append(["제목", "링크", "신문사"])
wb.save(filename='articles.xlsx')- 실행


가져온 뉴스 데이터 엑셀에 저장하기
from openpyxl import Workbook
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%B6%94%EC%84%9D"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
# ul태그 정보안의 각 기사 정보 가져오기
articles = soup.select("#main_pack > div.news.section._prs_nws_all > ul > li")
wb = Workbook()
ws1 = wb.active
ws1.title = "articles"
ws1.append(["제목", "링크", "신문사"])
# 각 기사의 제목 정보 가져오기
for article in articles:
title = article.select_one('dl > dt > a').text
url = article.select_one('dl > dt > a')['href'] # url
comp = article.select_one('span._sp_each_source').text.split(' ')[0].replace('언론사', '')
ws1.append([title, url, comp])
wb.save(filename='articles.xlsx')
driver.quit()
'Python' 카테고리의 다른 글
| 카카오톡 대화내용으로 워드 클라우드 만들기 (0) | 2020.10.03 |
|---|---|
| 이미지 웹 스크래핑 & 크롤링 #3 - 이메일 보내기 (0) | 2020.10.02 |
| 이미지 웹 스크래핑 & 크롤링 #1 - 웹에서 이미지 가져와 저장하기 (0) | 2020.10.01 |
| 웹 어플리케이션 (0) | 2020.08.29 |
| 네트워크 (0) | 2020.08.29 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- SQL
- vmware
- Variable allocation
- Disk System
- jdbc
- Disk Scheduling
- Spring
- HDFS
- linux
- Free space management
- hadoop
- 빅데이터
- Replacement Strategies
- aop
- Java
- SPARK
- mapreduce
- Allocation methods
- JSON
- 빅데이터 플랫폼
- I/O Services of OS
- RAID Architecture
- oracle
- springboot
- I/O Mechanisms
- 하둡
- gradle
- File Protection
- Flume
- maven
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함