
티스토리 뷰

- java project 생성

< build.xml >
- Ant를 통해서 jar 파일과 zip파일을 생성하는 코드
<?xml version="1.0" encoding="utf-8"?>
<project name="encore-Examples" default="build">
<property name="major-version" value="1" />
<property name="minor-version" value="0" />
<property name="build-number" value="0" />
<property name="version" value="${major-version}.${minor-version}.${build-number}" />
<property name="company-name" value="encore" />
<property name="project-name" value="hadoop-examples" />
<property name="general-lib" value="${company-name}-${project-name}.jar" />
<property name="general-src" value="${company-name}-${project-name}-src.zip" />
<property name="build-Path" location="." />
<property name="src.dir.src" location="${build-Path}/src" />
<property name="src.dir.bin" location="${build-Path}/bin" />
<property name="src.dir.build" location="${build-Path}/build" />
<target name="build" depends="build-lib, build-src" />
<target name="clean-all" depends="clean-lib, clean-src" />
<target name="clean-lib">
<delete file="${src.dir.build}/${general-lib}" />
</target>
<target name="clean-src">
<delete file="${src.dir.build}/${general-src}" />
</target>
<target name="build-lib" depends="clean-lib">
<jar destfile="${src.dir.build}/${general-lib}" basedir="${src.dir.bin}">
<manifest>
<attribute name="${project-name}-Version" value="${version}" />
</manifest>
</jar>
</target>
<target name="build-src" depends="clean-src">
<zip zipfile="${src.dir.build}/${general-src}" basedir="${src.dir.src}">
</zip>
</target>
</project>-
hadoop01에서 하둡을 실행하기 위한 jar 파일 가져오기

-
라이브러리 추가


-
HDFSTest01 : 사용자가 정의한 경로에 텍스트 파일을 생성하는 클래스
package hdfs.exam;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/*
* hdfs(하둡의 분산 파일 시스템)를 제어 - hadoop API로 제어
* api를 이용하여 hdfs에 파일을 생성하는 예제
*
* 사용자가 정의한 경로에 텍스트 파일을 생성하는 작업
*/
public class HDFSTest01 {
public static void main(String[] args) {
// 1. hdfs를 제어하기 위해서 설정파일에 정의된 내용을 api내부에서 접근할 수 있어야 한다.
// - 내부적으로 설정정보를 접근할 수 있도록 설정정보를 모델링한 객체를 생성
Configuration conf = new Configuration();
// 2. hdfs를 모델링 해놓은 객체 - hdfs를 접근할 수 있도록 객체를 생성
FileSystem hdfs = null;
// 3. hdfs로 출력할 수 있는 기능을 가지고 있는 출력 스트림
FSDataOutputStream hdfsout = null;
try {
hdfs = FileSystem.get(conf);
// 4. hdfs의 경로를 인식하는 객체를 이용해서 출력할 파일이 저장될 경로를 정의
// => 실행할 때 파일 경로를 명령문으로 입력받아서 사용할 수 있도록 명령행 매개변수
Path path = new Path(args[0]);
// 5. hdfs에 파일을 저장
hdfsout = hdfs.create(path); // fw = new FileWriter("파일명")과 동일작업
hdfsout.writeUTF(args[1]); // 명령행 매개변수로 입력한 문자열을 파일에 쓰기
} catch (IOException e) {
e.printStackTrace();
}
}
}-
build.xml 실행


-
실행 확인
-
build 폴더가 생성되며 jar파일과 zip파일 생성
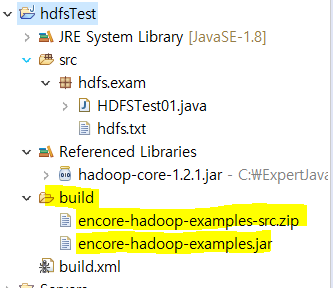
-
생성된 jar 파일을 hadoop01의 /home/hadoop 에 복사
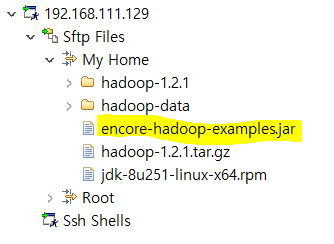
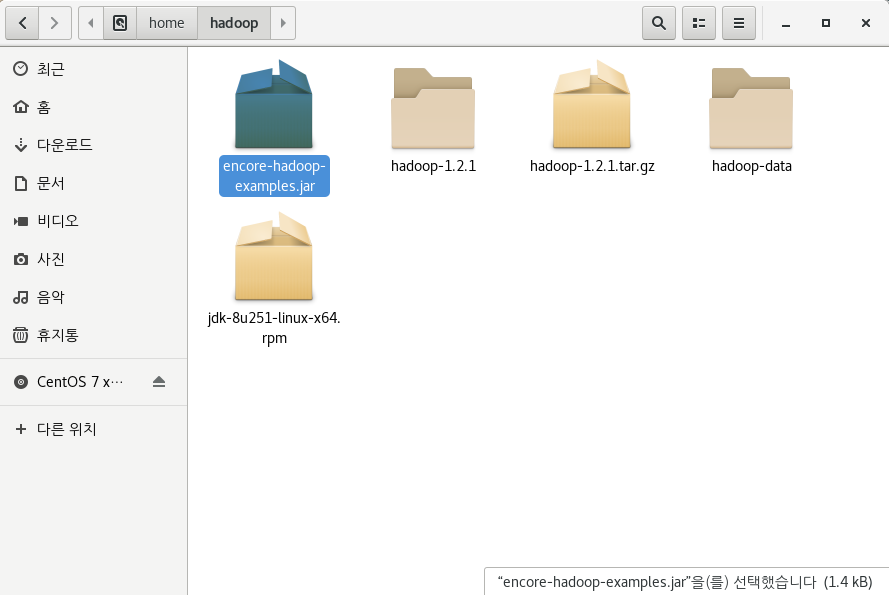
-
하둡으로 HDFSTest01 실행
-
명령행 변수로 path와 파일명을 넘겨준다

-
결과


-
HDFSTest02 : 사용자가 지정한 경로에 저장된 파일의 내용을 읽어서 콘솔에 출력 클래스
package hdfs.exam;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/*
* hdfs(하둡의 분산 파일 시스템)를 제어 - hadoop API로 제어
* api를 이용하여 hdfs에 파일을 생성하는 예제
*
* 사용자가 지정한 경로에 저장된 파일의 내용을 읽어서 콘솔에 출력
*/
public class HDFSTest02 {
public static void main(String[] args) {
// 1. hdfs를 제어하기 위해서 설정파일에 정의된 내용을 api내부에서 접근할 수 있어야 한다.
// - 내부적으로 설정정보를 접근할 수 있도록 설정정보를 모델링한 객체를 생성
Configuration conf = new Configuration();
// 2. hdfs를 모델링 해놓은 객체 - hdfs를 접근할 수 있도록 객체를 생성
FileSystem hdfs = null;
// 3. hdfs에 저장된 입력데이터를 읽을 수 있는 스트림
FSDataInputStream hdfsin = null; // FileReader fr = null;
try {
hdfs = FileSystem.get(conf);
// 4. hdfs의 경로를 인식하는 객체를 이용해서 출력할 파일이 저장될 경로를 정의
// => 실행할 때 파일 경로를 명령문으로 입력받아서 사용할 수 있도록 명령행 매개변수
Path path = new Path(args[0]);
// 5. hdfs에 파일을 저장
hdfsin = hdfs.open(path); // fw = new FileWriter("파일명")과 동일작업
String data = hdfsin.readUTF();
System.out.println("hdfs에서 읽은 데이터 :"+data);
} catch (IOException e) {
e.printStackTrace();
}
}
}-
build.xml을 Ant로 실행 후 생성된 jar파일을 hadoop01의 /home/hadoop 에 복사

- Practice
-
HDFSFileCopy.java
-
지정한 경로의 파일을 읽어서 지정한 경로로 복사하기
-
명령행매개변수를 이용
-
package hdfs.exam;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileCopy {
public static void main(String[] args) {
Configuration conf = new Configuration();
FileSystem hdfs = null;
FSDataInputStream hdfsin = null;
FSDataOutputStream hdfsout = null;
try {
hdfs = FileSystem.get(conf);
Path inpath = new Path(args[0]);
Path outpath = new Path(args[1]);
hdfsin = hdfs.open(inpath);
hdfsout = hdfs.create(outpath);
while(true) {
int data = hdfsin.read();
if(data == -1) {
break;
}
hdfsout.write((char)data);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(hdfsout!=null) hdfs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
-
실행

-
결과


'Hadoop' 카테고리의 다른 글
| 빅데이터 플랫폼 구축 #7 - MapReduce 연습 (0) | 2020.10.04 |
|---|---|
| 빅데이터 플랫폼 구축 #6 - MapReduce (0) | 2020.10.04 |
| 빅데이터 플랫폼 구축 #4 - Java,Hadoop , mapreduce (0) | 2020.10.03 |
| 빅데이터 플랫폼 구축 #3 - 가상머신 복제, 각 머신 연결 (0) | 2020.10.03 |
| 빅데이터 플랫폼 구축 #2 - CentOS 설치 (0) | 2020.10.02 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 빅데이터
- Disk System
- File Protection
- I/O Services of OS
- 하둡
- SPARK
- aop
- Flume
- Disk Scheduling
- Replacement Strategies
- Free space management
- RAID Architecture
- Allocation methods
- HDFS
- hadoop
- 빅데이터 플랫폼
- JSON
- Java
- jdbc
- maven
- oracle
- I/O Mechanisms
- gradle
- linux
- Spring
- Variable allocation
- mapreduce
- springboot
- vmware
- SQL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함