
티스토리 뷰
3. 가상머신 복제하기
- 가상머신이 네 대 있다 가정하고 네 개의 가상머신을 만들어준다.
: ip확인
-
머신 복제하기
-
문서\Virtual Machines - 폴더를 복사

-
VMware에서 머신 열기


-
머신 이름 변경


-
hadoop01 실행
-
root계정 로그인

-
터미널 열기

-
인터넷 연결 확인

-
VMWare 실행 hadoop02 실행
-
root 계정 로그인

-
머신 ip 다른지 확인

-
hadoop03 , hadoop04 머신 실행
-
ip 다른지 확인

-
머신 간 연결 확인하기
-
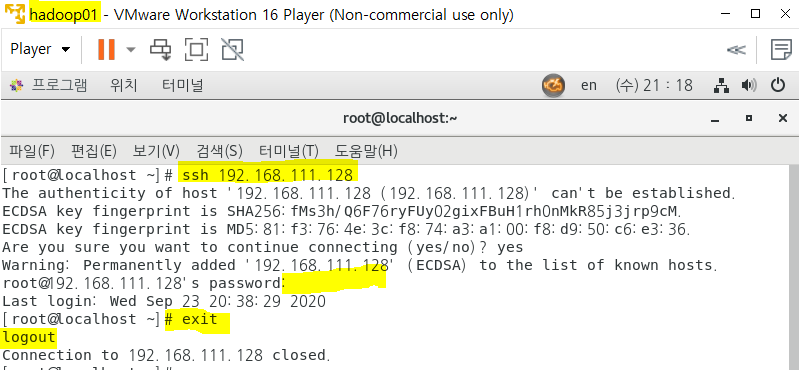
hadoop01 머신에서 hadoop02 머신 연결

-
hostname 변경하기
-
각 머신 이름으로 변경

-
변경 확인

4. 하둡 서버를 구축하기 위한 클러스터링 설정하기
-
방화벽이 설정되어 있으면 하둡 실행이 안된다.
-
현재 실행중인 서비스 리스트

-
방화벽 상태정보

-
방화벽 종료( 현재 상태에서 종료 재부팅시 다시시작 됨)

-
계속 적용하려면 disable 해야한다.

-
재부팅 후 확인


-
hadoop02, 03, 04 머신도 모두 disable 한다.
-
DNS설정

-
접속확인

-
hadoop01 머신에 있는 /etc/hosts 파일을 각 머신에 복사
-
다른머신에 복사는 scp 명령어 사용
-
scp 복사할 파일위치 복사할 머신이름:/복사할 위치

-
확인

-
접속 확인
-
hadoop01 -> hadoop02 -> hadoop03 -> hadoop04 -> hadoop01 로 접속

-
들어간 만큼 빠져나온다

5. 각종 프로그램 설치
- SSH 프로토콜 설정
- hadoop을 테스트하기 위해서는 자바가 반드시 필요하므로
- java, hadoop을 설치하고 설정을 한 후 테스트한다.
-
각 노드간 통신을 하기 위한 key 생성

-
id_rsa : 비밀키
-
id_rsa.pub : 공개키

-
hadoop01 : NameNode -> 비밀키
-
hadoop02, hadoop03, hadoop04 : DataNode -> 공개키
-
공개키를 hadoop02, hadoop03, hadoop04에 복사
-
NameNode 와 DataNode 사이의 통신 DataNode끼리는 X

-
접속 확인
-
암호확인 없이 키로 접속

'Hadoop' 카테고리의 다른 글
| 빅데이터 플랫폼 구축 #5 - HDFS 활용 (0) | 2020.10.04 |
|---|---|
| 빅데이터 플랫폼 구축 #4 - Java,Hadoop , mapreduce (0) | 2020.10.03 |
| 빅데이터 플랫폼 구축 #2 - CentOS 설치 (0) | 2020.10.02 |
| 빅데이터 플랫폼 구축 #1 - VMware 설치, 네트워크 설정 (0) | 2020.10.02 |
| Pig (0) | 2020.08.19 |
- Total
- Today
- Yesterday
- gradle
- Flume
- 하둡
- hadoop
- File Protection
- 빅데이터
- I/O Services of OS
- Allocation methods
- linux
- Disk System
- mapreduce
- oracle
- HDFS
- jdbc
- aop
- Variable allocation
- maven
- SQL
- JSON
- RAID Architecture
- Disk Scheduling
- Free space management
- vmware
- Java
- SPARK
- Spring
- I/O Mechanisms
- Replacement Strategies
- springboot
- 빅데이터 플랫폼
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |