
티스토리 뷰

설치


-
버전에 맞도록 다운



-
압축 해제

-
스파크 실행(scala)

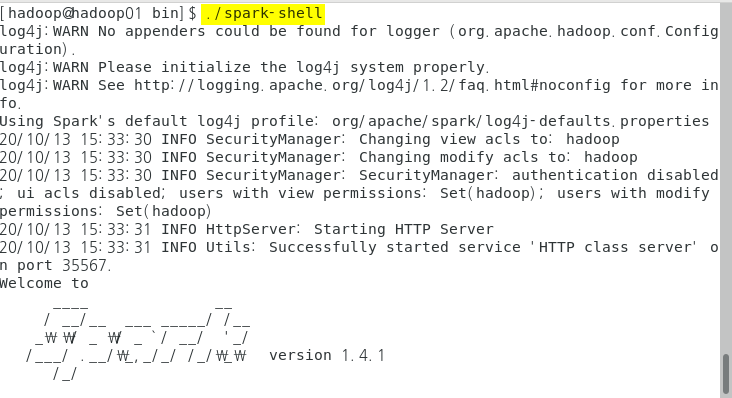

-
환경변수 설정(.hashrc)

-
임시적용

설정
-
sbin : 실행할 수 있는 shell파일들

-
master실행
-
hadoop이 실행 중 이어야 함

-
spark master 관리 페이지

-
slave실행 (설정 전)

-
worker는 1개가 기본값

-
master, slave 종료

-
세팅 파일 생성
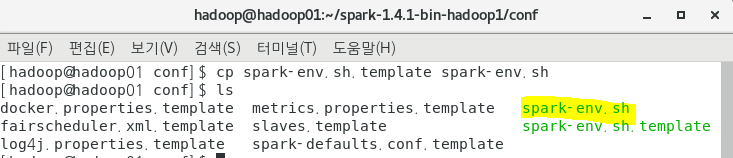

-
master , slave 재실행
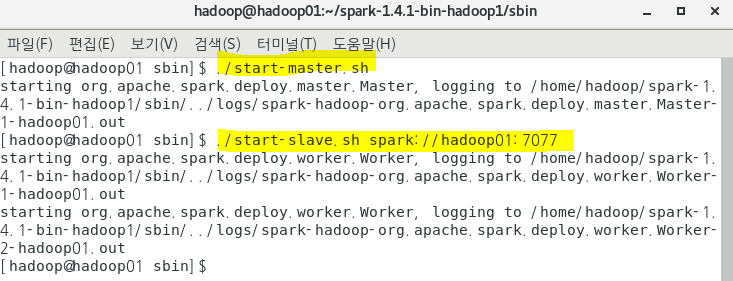
-
확인

프로젝트 생성
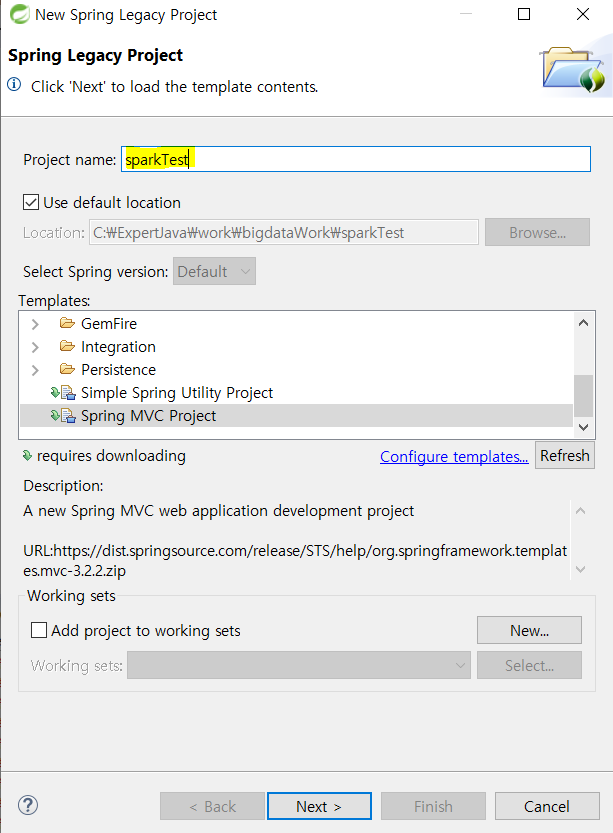


-
spark dependency (spring버전 4.2.4)
<!-- Spark dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.4.1</version>
</dependency> -
테스트 데이터 생성

< SparkTestStep1.java >
package bigdata.spark.basic;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class SparkTestStep1 {
public static void main(String[] args) {
// 1. Spark설정정보를 갖고 있는 객체를 생성
SparkConf conf = new SparkConf();
conf.setAppName("firstProgramming");
//2. Master셋팅
// => spark에게 어떤 식으로 클러스터에 접속할지 알려준다.
// => local은 한 개의 쓰레드나 단일 로컬 머신에서 실행할 때 접속할
// 필요가 없다는 것을 알려주는 특수값
conf.setMaster("local");
//3. Application이 spark와 연동되기 위해 SparkContext를 작성해야 한다.
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//4. RDD를 생성
// => spark내부에서 사용되는 핵심 데이터모델
// => spark내부에서 test.txt를 처리하기 위해서
// text.txt로 RDD를 생성
JavaRDD<String> textRDD = sparkContext.textFile("src/main/java/data/test.txt");
//5. RDD를 구성하는 구성요소를 출력
// 1) 구성요소의 갯수를 출력
// 2) RDD처리 - 원하는 데이터 선택, mapreduce적용, ...
long data = textRDD.count();
System.out.println("RDD갯수=> " + data);
textRDD.foreach(line -> System.out.println(line));
}
}

'Hadoop' 카테고리의 다른 글
| 빅데이터 플랫폼 구축 #18 - Spark : WordCount (0) | 2020.10.23 |
|---|---|
| 빅데이터 플랫폼 구축 #17 - Spark : flatMap (0) | 2020.10.23 |
| 빅데이터 플랫폼 구축 #15 - 커스터마이징(2) : 보조정렬 (0) | 2020.10.21 |
| 빅데이터 플랫폼 구축 #14 - 커스터마이징(1) : Combiner (0) | 2020.10.18 |
| 빅데이터 플랫폼 구축 #13 - Flume (2) (0) | 2020.10.11 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- Disk Scheduling
- linux
- mapreduce
- I/O Mechanisms
- Free space management
- SPARK
- maven
- hadoop
- I/O Services of OS
- 빅데이터 플랫폼
- Java
- 하둡
- SQL
- JSON
- Replacement Strategies
- gradle
- springboot
- File Protection
- oracle
- 빅데이터
- Variable allocation
- Flume
- HDFS
- Disk System
- RAID Architecture
- aop
- jdbc
- Allocation methods
- Spring
- vmware
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함