
티스토리 뷰
Spark
-
분석엔진
-
하둡보다 100배이상 빠름
-
spark를 개발할 수 있는 언어는 scala, java, python, R
-
spark라이브러리는 spark core, spark sql, spark streaming, MLlib(머신러닝), GraphX
-
spark는 대규모 데이터의 처리를 위한 통합 분석 엔진
-
spark의 구성요소
-
SparkContext( JavaSparkContext ) : spark가 동작하기 위해서 필요한 기본 정보를 가지고 있는 객체로 spark가 제공하는 다양한 서비스와 기능을 직접 사용할 수 있는 기본 클래스
-
RDD(Resilient Distributed DataSet)
-
스파크에서 사용하는 기본 데이터 구조
-
스파크에서는 내부적으로 사용하고 처리하는 모든 데이터를 RDD타입으로 처리
-
RDD를 만들어서 메모리에 적재시켜놓고 작업하는데 변경할 수 없다.
-
RDD는 java의 Stream과 비슷하지만 다른 객체
-
RDD -> Stream 으로 변환은 가능
-
Stream -> RDD 로 변환은 불가능
-
-
RDD는 SparkContext에 의해서 생성
-
RDD는 파티션으로 나누어서 관리가 된다.
-
RDD를 처음 생성할 때 HDFS에서 데이터를 가져와서 만들고 메모리에서 처리를 하고 결과를 HDFS에 저장
-
RDD연산
-
변환(Transformations)
-
RDD에서 새로운 RDD가 생성되는 경우
-
filter, map, flatMap, mapPartitions, distinct, groupByKey, reduceByKey, sortByKey, join
-
-
액션(Actions)
-
RDD에서 다른 데이터 타입으로 변환되거나 완료되는 경우
-
count, first, collect, foreach
-
Actions분류의 메소드가 호출이 되어야 결과를 볼 수 있다.
-
-
RDD분산
-
RDD는 크기가 크기 때문에 파티션으로 잘라서 분산시켜서 처리
-
-
단어 분석
< simple-words.txt >
cat
dog
.org
cat
cat
&&
tiger
dog
100
tiger
cat< SparkWordTest01.java >
package bigdata.spark.basic;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class SparkWordTest01 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("simpleTest01")
.setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
// 1. textFile을 불러와서 출력
// JavaRDD<String> wordRDD =
// sparkContext.textFile("src/main/java/data/simple-words.txt");
// wordRDD.foreach(word -> System.out.println(word));
// 2. 길이가 4 이상 출력
// sparkContext.textFile("src/main/java/data/simple-words.txt")
// .filter(word -> word.length()>=4)
// .foreach(word -> System.out.println(word));
// 3. 영어, 한국어 만 출력 -> cat만 출력
// sparkContext.textFile("src/main/java/data/simple-words.txt")
// .filter(word -> word.matches("[A-z가-힣]+"))
// .filter(word -> word.equalsIgnoreCase("cat"))
// .foreach(word -> System.out.println(word));
// 4. 모든 단어가 영문자로 구성되면서 c로 시작하는 문자를 고르고 모두 대문자로 변환해서 출력하기
// sparkContext.textFile("src/main/java/data/simple-words.txt")
// .filter(word -> word.matches("([A-z]+)"))
// .filter(word -> word.startsWith("c"))
// .map(String :: toUpperCase)
// .collect()
// .forEach(word -> System.out.println(word));
sparkContext.close();
}
}
-
결과
-
textFile을 불러와서 출력

2. 길이가 4 이상 출력

3. 영어, 한국어 만 출력 -> cat만 출력

4. 모든 단어가 영문자로 구성되면서 c로 시작하는 문자를 고르고 모두 대문자로 변환해서 출력하기
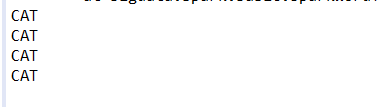
FlatMap
< FlatMapTest.java >
package stream;
import java.util.Arrays;
import java.util.List;
public class FlatMapTest {
public static void main(String[] args) {
List<String> subjectlist = Arrays.asList(
"java, favaFx",
"jdbc, html, css, javascript",
"servlet, jsp, jquery, spring",
"hadoop, hive, flume, sqoop, spark, mahout"
);
subjectlist.stream()
.map(data -> data.split(","))
.forEach(data -> System.out.print(data + " "));
System.out.println();
System.out.println();
subjectlist.stream()
.flatMap(data -> (Arrays.asList(data.split(","))).stream())
.forEach(data -> System.out.print(data + " "));
}
}-
결과

'Hadoop' 카테고리의 다른 글
| 빅데이터 플랫폼 구축 #19 - Spark : HDFS 활용 (0) | 2020.10.24 |
|---|---|
| 빅데이터 플랫폼 구축 #18 - Spark : WordCount (0) | 2020.10.23 |
| 빅데이터 플랫폼 구축 #16 - Spark : 설치 및 테스트 (0) | 2020.10.22 |
| 빅데이터 플랫폼 구축 #15 - 커스터마이징(2) : 보조정렬 (0) | 2020.10.21 |
| 빅데이터 플랫폼 구축 #14 - 커스터마이징(1) : Combiner (0) | 2020.10.18 |
- Total
- Today
- Yesterday
- 빅데이터 플랫폼
- aop
- Java
- linux
- Disk System
- I/O Services of OS
- Disk Scheduling
- vmware
- springboot
- Replacement Strategies
- 하둡
- SPARK
- HDFS
- 빅데이터
- jdbc
- RAID Architecture
- Allocation methods
- gradle
- hadoop
- SQL
- Free space management
- File Protection
- I/O Mechanisms
- Variable allocation
- Spring
- JSON
- mapreduce
- maven
- oracle
- Flume
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |